A Tale of Two Analytic Engines
Now, how do we get the cube to use the dimension? In Pentaho Analysis Services, there is a concept of Dimension Usage in the cube. This allows for shared dimensions. To create a dimension usage on the ResellerSales cube, perform the following steps:
In this first head-to-head comparison, we pit Microsoft SQL Server Analysis Services (SSAS) 2008 against Pentaho BI's Analysis Services. As mentioned in the introductory post, in-memory analytic engines aren't exactly new hat. In fact, the inspiration for these engines came from very simple spreadsheet applications, hence the origins of Essbase's name -- "Extended Spread Sheet Database." Despite their age, the benefits of analytic engines remain the same: data retrieval and ad-hoc analysis at lightning speeds. Because most of the data is persisted in RAM, the speed at which you retrieve the data is only limited by your network speed and your user interface's rendering. With that in mind, we have two analytic engines here that drew inspiration from similar roots, but go about their implementations differently.
Microsoft SQL Server Analysis Services has actually been around since SQL Server 7, thanks to Big Redmond's acquisition of Panorama Software. It has only been a recent development, starting with SQL Server 2005, that Microsoft has made a serious push into the BI space, literally offering its entire BI stack for free with a SQL Server 2005 (and then later, 2008) Standard Edition license. Microsoft innovated the now ubiquitous Multi-Dimension Expression (MDX) query, and has made strides in usability, deeply integrating the SQL Server BI platform to all of its core enterprise offerings, Microsoft Office and Microsoft Sharepoint, as well as its well renowned integrated development environment, Visual Studio.
Pentaho Analysis Services, aka Mondrian in the open source world, is a relative newcomer to the BI marketplace. Started by industry veterans from the defunct Arbor Software (where Essbase was incubated and released) at the turn of the 21st century, this Java-based analytic platform began its roots as an open source platform, along with the other components of Pentaho BI. The goal of its founders was to create a powerful, flexible, cohesive, scalable, and cost-effective platform, meeting or exceeding the capabilities of its commercial conglomerate counterparts. Who better to architect and develop such a solution but some of the very pioneers of the BI movement? PAS is the core of the Pentaho BI stack, offering seemingly the same capabilities as other analytic engines in the market.
With the history of both analytic engines in mind, let's take a deep dive at both, using AdventureWorks as the star schema base. For the impatient, I have published all the artifacts produced in this blog post on my source control system, which grants everyone read access. If you have a Subversion client, point to https://edg.sourcerepo.com/edg/PentahoAdventureWorks
The Requirements
We will test both analytic engines' and corresponding design tools' capabilities in addressing the following requirements for the AdventureWorks data warehouse:
Pentaho Analysis Services (PAS)
Setup
The standard setup of Pentaho Business Analytics is collocating all components on the same server, which is also the default for SQL Server 2008 BI. We won't get into how to optimally arrange the platforms in a distributed format for the purposes of this head-to-head, but know that Pentaho does have the ability to scale out in a distributed format, if needed.
The setup for Pentaho Business Analytics on Ubuntu is a cinch. Just have a standard Ubuntu Server ready with no components (save for SSH) installed, and then run the binary, follow the instructions, change the defaults if you wish, and voila. PBA can be up and running on a Linux Server in about 10 minutes. The primary front-end for Pentaho Business Analytics is a component called Pentaho User Console, a web-based application.

In terms of PAS, like the SSAS engine, it is hosted in-memory. Pentaho describes the PAS as an "ROLAP engine", which may confuse people accustomed to SSAS. In PAS world, "ROLAP" stands for "relational OLAP", whereas in SSAS, it stands for a type of expensive in-memory storage for its cubes called "real-time OLAP". It's important to note the distinction, as they have completely different uses.
Connection and Schema Creation
A user or developer can go about deploying cubes on their Pentaho one of two ways: define a new Data Source on the Pentaho User Console (more for the power-user) or create a proper schema using the desktop application Pentaho Schema Workbench. As a developer, there are many limitations of the first option -- you may only create one cube at a time and cannot fully define the whole domain of your data warehouse, no advanced security settings, inability to create complex calculated members, etc. So, for the purposes of this shootout, we will cover the proper "developer" way of creating and deploying cubes -- using Pentaho Schema Workbench. I have installed it on my local Windows 7 machine and will be developing on Windows whilst deploying to the Linux server.
When you first launch Pentaho Schema Workbench, the first thing you must define is a connection to your data warehouse, which is accomplished by clicking Options --> Connection...

Note that Pentaho supports most all database platforms -- however, keep in mind that, if you want a certain database connection to work in development time, you must download its respective JDBC driver and drop it into the \schema-workbench\drivers subfolder on your development machine. Likewise, on the server, be sure to drop the .JAR file for that JDBC driver into the /tomcat/lib subfolder to ensure functionality. We are using out of the box connectivity to MySQL, so we don't have any exotic setup for this review.
Once a connection is established, you may begin creating your cube and dimension structure by clicking on File --> New --> Schema.

Nothing too interesting yet, but we have our foundation laid down. A MySQL connection to AdventureWorksDW2008 defined in an as-of-yet unsaved Pentaho schema file. To those familiar with the cohesiveness of the Visual Studio IDE, the first impression of the Pentaho Schema Workbench is that it looks a little...bare bones. The analogy I can provide is that Visual Studio is like making a painting, but having a bunch of tracing templates ready to use, whereas the Schema Workbench seems like literally a blank canvas. We can click on the topmost "Schema" node and define some attributes, so let's call our schema "AdventureWorksDW".
Cube Creation
Now let's go and define our analytic structure, starting with the cubes. We'll begin with the cube that will be created against FactResellerSales.
Dimensions can be created on two levels in Pentaho. The first level is local to the cube -- that is, dimensions that are only accessible by that cube only. While this can be useful for dimensions that are only in use by one cube, in the AdventureWorks example, most all of the dimensions are shared across fact tables. This brings us to the second level where we can define dimensions -- schema-wide. We will create all dimensions at this level for this exercise, so to attain maximum flexibility.
First, right click at the "Schema" node then click on "Add Dimension". You should get the "New Dimension 0" as a child of Schema now.
Just to show an example of how the dimension creation process works, let's walk through the creation of adding the "DimEmployee" (we'll call it Employee in our schema) table.
Repeat steps 12-19 for the rest of the dimensional attributes for DimEmployee. (The caveat being, make sure to select the proper "type" for the data you're pulling up. Ex. varchar = string, datetime = date, etc). Also, repeat the process above for each dimension linked up to ResellerSales.
The schema should now look something similar to below.

With the history of both analytic engines in mind, let's take a deep dive at both, using AdventureWorks as the star schema base. For the impatient, I have published all the artifacts produced in this blog post on my source control system, which grants everyone read access. If you have a Subversion client, point to https://edg.sourcerepo.com/edg/PentahoAdventureWorks
The Requirements
We will test both analytic engines' and corresponding design tools' capabilities in addressing the following requirements for the AdventureWorks data warehouse:
- The analytic engine shall be able to form the ResellerSales cube and shared dimensions within a common domain
- The analytic engine shall be able to define a simple calculated member against the cube created against ResellerSales called "Net Profit or Loss". Calculation: (Extended Amount - Total Product Cost)
- The analytic engine shall be able to define a simply hierarchy in DimSalesTerritory that illustrates the following: Region --> Country --> Group
- The analytic engine shall implement the following read security rules on FactResellerSales: only Sales Managers and Executives can read FactInternetSales and FactReseller sales data
Pentaho Analysis Services (PAS)
Setup
- Ubuntu 11.10 (aka Oneiric Ocelot) Server
- 2 GB RAM
- 20 GB HDD
- Apache TomCat Server
- MySQL Server (collocated with PAS)
- Source Control Link: Click Here
- Pentaho User Console (web-based)
- Pentaho Schema Workbench (desktop application)
The standard setup of Pentaho Business Analytics is collocating all components on the same server, which is also the default for SQL Server 2008 BI. We won't get into how to optimally arrange the platforms in a distributed format for the purposes of this head-to-head, but know that Pentaho does have the ability to scale out in a distributed format, if needed.
The setup for Pentaho Business Analytics on Ubuntu is a cinch. Just have a standard Ubuntu Server ready with no components (save for SSH) installed, and then run the binary, follow the instructions, change the defaults if you wish, and voila. PBA can be up and running on a Linux Server in about 10 minutes. The primary front-end for Pentaho Business Analytics is a component called Pentaho User Console, a web-based application.

 |
| The Pentaho User Console Login and Main Page, respectively |
Connection and Schema Creation
A user or developer can go about deploying cubes on their Pentaho one of two ways: define a new Data Source on the Pentaho User Console (more for the power-user) or create a proper schema using the desktop application Pentaho Schema Workbench. As a developer, there are many limitations of the first option -- you may only create one cube at a time and cannot fully define the whole domain of your data warehouse, no advanced security settings, inability to create complex calculated members, etc. So, for the purposes of this shootout, we will cover the proper "developer" way of creating and deploying cubes -- using Pentaho Schema Workbench. I have installed it on my local Windows 7 machine and will be developing on Windows whilst deploying to the Linux server.
When you first launch Pentaho Schema Workbench, the first thing you must define is a connection to your data warehouse, which is accomplished by clicking Options --> Connection...

Note that Pentaho supports most all database platforms -- however, keep in mind that, if you want a certain database connection to work in development time, you must download its respective JDBC driver and drop it into the \schema-workbench\drivers subfolder on your development machine. Likewise, on the server, be sure to drop the .JAR file for that JDBC driver into the /tomcat/lib subfolder to ensure functionality. We are using out of the box connectivity to MySQL, so we don't have any exotic setup for this review.
Once a connection is established, you may begin creating your cube and dimension structure by clicking on File --> New --> Schema.
Nothing too interesting yet, but we have our foundation laid down. A MySQL connection to AdventureWorksDW2008 defined in an as-of-yet unsaved Pentaho schema file. To those familiar with the cohesiveness of the Visual Studio IDE, the first impression of the Pentaho Schema Workbench is that it looks a little...bare bones. The analogy I can provide is that Visual Studio is like making a painting, but having a bunch of tracing templates ready to use, whereas the Schema Workbench seems like literally a blank canvas. We can click on the topmost "Schema" node and define some attributes, so let's call our schema "AdventureWorksDW".
Cube Creation
Now let's go and define our analytic structure, starting with the cubes. We'll begin with the cube that will be created against FactResellerSales.
- Right click at the topmost "Schema" node then click on "Add Cube"
- In the "name" field, type in ResellerSales
- Right click on the cube level (now named ResellerSales) then click "Add Table"
- In the new "Table for ResellerSales Cube" child, expand the "name" dropdown and select FactResellerSales.
- Right click on the cube level then click "Add Measure"
- In this new "Measure for ResellerSales Cube" child member, type in "Unit Price" for the name
- Expand the "aggregator" dropdown and select "sum"
- Expand the "column" dropdown, then select "Fact Reseller Sales -> Unit Price - DECIMAL(10,0)"
- In the formatString property, type in #,###
- Expand the dataType dropdown and select Numeric
Repeat steps 4-9 above for all the measures you want to pull down from FactResellerSales. For all the other cubes you want included in this schema, obviously repeat the entire process.
Creating Calculations
Creating calculations on the cube is a relatively straightforward process in Schema Workbench.
Creating Calculations
Creating calculations on the cube is a relatively straightforward process in Schema Workbench.
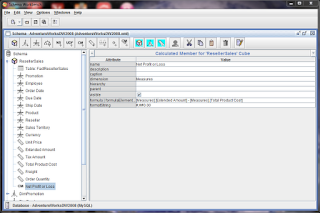
- Right click on the ResellerSales cube, then click "Add Calculated Member"
- In the newly created Calculated Member node, change the name to "Net Profit or Loss"
- The dimension should be "Measures"
- The formula should be [Measures].[Extended Amount] - [Measures].[Total Product Cost]
- The formatString should be #,##0.00
The calculated member should look similar to the example below.
Dimension Creation
Dimensions can be created on two levels in Pentaho. The first level is local to the cube -- that is, dimensions that are only accessible by that cube only. While this can be useful for dimensions that are only in use by one cube, in the AdventureWorks example, most all of the dimensions are shared across fact tables. This brings us to the second level where we can define dimensions -- schema-wide. We will create all dimensions at this level for this exercise, so to attain maximum flexibility.
First, right click at the "Schema" node then click on "Add Dimension". You should get the "New Dimension 0" as a child of Schema now.
Just to show an example of how the dimension creation process works, let's walk through the creation of adding the "DimEmployee" (we'll call it Employee in our schema) table.
- In the newly created dimension above, change the name to "DimEmployee" (we'll call it the appropriate "Employee" dimension name when we use this dimension in cubes later).
- In the description, we'll specify some information.
- In foreign key, expand the dropdown and select "FactResellerSales --> EmployeeKey - INTEGER(10)".
- The type should be "StandardDimension"
- In the Caption, type in AdventureWorks Employee"
- Expand this new dimension. A default "New Hierarchy 0" should've been created.
- This is the topmost hierarchy which will be the parent for "All Employees". Blank out the "name" field for New Hierarchy 0 then press enter.
- In the allMemberName, type in "All Employees"
- For the primaryKey field, select EmployeeKey
- Right click on this new hierarchy (should now be labelled "default") then click "Add Table"
- In the new "Table for Hierarchy" child, select DimEmployee in the name dropdown.
- Left click back to the "default" node under Employee. Expand the primaryKey field then select DimEmployee -> EmployeeKey - INTEGER(10).
- Right click back on the "default" property. Now click "Add Level"
- In the name field for this new "Level for Hierarchy" child, type in "First Name"
- In the "table" dropdown, select DimEmployee.
- In the "column" dropdown, select "DimEmployee --> FirstName --> VARCHAR(50)"
- In the "type" dropdown, select String.
- For levelType, select Regular
- for hideMemberIf, select Never
Repeat steps 12-19 for the rest of the dimensional attributes for DimEmployee. (The caveat being, make sure to select the proper "type" for the data you're pulling up. Ex. varchar = string, datetime = date, etc). Also, repeat the process above for each dimension linked up to ResellerSales.
The schema should now look something similar to below.

Now, how do we get the cube to use the dimension? In Pentaho Analysis Services, there is a concept of Dimension Usage in the cube. This allows for shared dimensions. To create a dimension usage on the ResellerSales cube, perform the following steps:
- Right click on the "ResellerSales" node then click on "Add Dimension Usage"
- For the name of the Dimension Usage, type in "Employee"
- For the foreignKey of the dimension usage, select EmployeeKey
- For the source of the dimension usage, select DimEmployee (the shared dimension we created previously)
The steps above create some configuration for our cube to use the "DimEmployee" shared dimension, and call it the "Employee" dimension within the context of the ResellerSales cube.
Creating Hierarchies
When we get to the creation of the Sales Territory dimension, one will notice that it has a hierarchical structure. Specifically, our data is organized such that SalesTerritoryGroup is the parent of SalesTerritoryCountry. In turn, SalesTerritoryCountry is the parent of SalesTerritoryRegion. In this example, I've simplified the naming conventions to be Group, Region, and Country.
To define this hierarchical structure, assuming these fields are already created under the same default hierarchy as explained above, creating this tiered relationship is as follows in Schema Workbench:
Unfortunately, defining the hierarchy in the Sales Territory dimension above gives us some drawbacks in the dimension. First, the way data will come up will only be if you first drop the Group attribute to an axis first, then the Country, then the Region. If you drop the Country attribute into an axis directly, your report will yield no data.
This is a little curious, as in the SSAS world, this does not happen. In fact, defining the hierachy in SSAS such as the above makes the parent-child relationships easier to read and has no effect on dropping any of the child attributes to an axis to slice and dice.
Again, my new-ness to Pentaho may have something to do with this, and I will explore a resolution of this hierarchy model as I understood it from SSAS. Until then, I will have to take points away from Pentaho for an unclear definition of how the hierarchies should be defined and consumed. For my model, I have just removed the hierarchy in the Sales Territory dimension altogether so that the slice and dice capability is at least usable for this dimension.
Applying Security
Security is also implemented with Pentaho Analysis Services. This obviously will be defined at the Schema level, as security spans across all cubes and dimensions. To setup our security such that only Resellers and Executives can actually see the ResellerSales cube, the following steps should be taken:
One note about the security model -- it is not easy to implement out of the box. Per the Mondrian documentation, you can either embed the Role in the connection string or programmatically set it. All I could think of is how ugly this is. The security implementation of an analytic engine should be a basic implemented feature, but Mondrian appears to have a separate security model from the Pentaho User Console. This definitely may be a dealbreaker for many folks.
Publishing the PAS Schema
So, assuming you've completed the steps above for the rest of the dimensions within AdventureWorksDW2008 and linked it them up to the ResellerSales cube, we essentially have a ready to publish schema.
Publishing from Schema Workbench is relatively straightforward. Simply click File --> Publish. A popup window appears which asks you to specify the URL to your Pentaho User Console, the Publish Password, and a Username/Password combination with sufficient rights to publish.
Click OK, and Schema Workbench then makes a connection to your Pentaho repository. Finally, select a destination for this new schema, specify the named connection on your Pentaho server which the schema will use to aggregate its data, and optionally, publish this schema as part of PAS' XMLA service. Click on Publish, and then your schema will now be accessible as part of your Pentaho install.
Schema Creation/Publishing Summary
Admittedly, coming from the land of SQL Server 2008 BI, the development process feels incredibly cumbersome with Pentaho. The Schema Workbench should try to adopt something as smooth as an SSAS project on BIDS, whereby the developer simply adds all the dimension and fact tables visually on a view, drag and drop PK/FK relationships among the dimension and fact tables, then creates cubes based on this view, and then finally the tool should be smart enough to create the skeleton for all the dimensions with the fact measures linked up. The definition of the dimensional attributes, properties, and hierarchies should come after this quick vetting out process. It's a small thing, but the fact that Schema Workbench can't create a skeleton structure for me given a relational star schema is a bit annoying.
Anyway, creating your analytic schema will take a bit of time in Pentaho, even if it's a relatively simple star schema with nothing crazy related to hierarchies or calculated members. Calculated members are straightforward. However, the hierarchies, while straightforward to construct, don't seem to behave in the way that I would expect them to behave. Furthermore, the security model really is, for lack of a better term, primitive. I don't understand how PAS got through three version releases without implementing security integration with the rest of the Pentaho suite, it's just mind-boggling.
In terms of publishing the schema, the process is relatively straightforward from Schema Workbench. There doesn't appear to be an automated way of deploying cubes (as part of a Continuous Integration Server, for example), but the structure is relatively simple. The schema file itself is an XML file that will get dropped somewhere in the repository and making it available for consumption is a matter of updating the /pentaho-solutions/system/olap/datasources.xml file.
To sum up, the creation and publishing of the schemas in Pentaho, while functional, seems a bit rough around the edges. This might be slightly off-putting for anyone who came from the SQL Server BI platform first.
Consumption of Data
So, now we get to the fun part -- using the data schema we just published. We've got a nice Reseller Sales cube using a bunch of Shared Dimensions defined above and published to our Pentaho server. Let's do a little slicing and dicing!
The primary user interface for the Pentaho BI stack is the User Console. On a default install, it sits on port 8080 of your Apache Tomcat server. So, let's pop into the User Console and see where we can get at this data.

I must admit, this is one of the components of Pentaho that I've absolutely grown to love. In terms of user interface presentation and coherence, I believe Pentaho really has beaten Microsoft here. Whereas a SQL Server 2008 BI solution is disjointed from the start (until you develop some Sharepoint site to sit on top with a little PowerPivot and some SSRS reports), Pentaho feels...unified right out of the gate. Everything through the web-based User Console first.
We'll go into a deep dive of the Pentaho User Console in a later article which we review the overall "out of the box" user presentation of each platform, but from a preliminary perspective, I really prefer the Pentaho web-based UI.
The way to do some ad-hoc slice and dice analysis on a published cube on the User Console is simple. Click on New Analysis, select the cube, and you're off!

The report obviously starts off blank, but if you're familiar with any analytic tool, the next part should be straightforward. Simply drop what measures you want to aggregate onto the report canvas. Afterwards, drop in whatever dimensional attribute you want along the row and column axes. For this example, let's measure Net Profit or Loss. Then, let's see the data by Department Name (off the Employee Dimension) across the rows and then by Fiscal Year across the columns.
The data is presented, as we expect, in lightning speed. However, one quirk I see with the Analyzer Report is that it does not aggregate by dimensional attribute...it only seems to aggregate by the dimension itself. In other words, in SSAS, the above slice would've come up with one row only, with Net Profit or Loss aggregated by the Department Name. However, it appears that the Pentaho web-based Analyzer Report does not have this built-in functionality. The "Sales" department name above repeats by the number of employees we have in the Employee dimension. How curious.
Of course, this could be the way I designed the dimension, so I've floated up this question to the Pentaho Forums, hoping to gain insight, if it is indeed a system limitation or simply incorrect design on my part for the dimension. I will update this article as soon as I get a response back. If it is a system limitation, that would be a little disheartening, as this web-based analytic tool is otherwise brilliant.
To demonstrate its flexibility, let's slice out some data that won't produce repeat data. Let's measure Net Profit or Loss by Region (off of the Sales Territory dimension) on the column axis and then dragging the Fiscal Year dimensional attribute over to the row axis. Changing your sliced data is as simple as clicking and dragging the Department Name dimension from the row axis and into a garbage can that appears in the lower right hand corner. Then, drag the Fiscal Year dimensional attribute from the column axis to the row axis. Finally, drag over the Region dimensional attribute from the Sales Territory dimension and drop it on the column axis.
Now, let's get a little fancy. Let's see this data plotted across a line graph. To do this, there is a Pie-Chart shaped icon on the upper right hand corner of the report (to the right of "View As"). To the right of this pie chart is a downward arrow. Click on the downward arrow then select "Line".

As you might have seen from the other options, there are multiple visualizations of data you can make right off of the interface. Very, very slick. Let's save this report off before we continue. If you haven't already, in your Pentaho repository, create an AdventureWorksDW2008 folder, and then create an Analysis subfolder underneath that. Click File --> Save As. Browse to this subdirectory and let's call this report "Net Profit or Loss by Region". Finally, click Save, and then when you browse to this subdirectory in the repository, you'll see our fancy new report.

Let's examine some export options. Web-based is nice and all, but at times, you will need to save off to a file format that can be read by stakeholders locally. The Analyzer Report offers the ability to export to PDF, Excel, or CSV. Simply click on the More option above the report, select Export Report, then select your desired format. See examples below of the export formats we can achieve.

Without going into too much detail, the PDF reports in particular look very slick, complete with a cover page, any graphs (like the one above) we create, and report parameters in the last page.
On Excel, the data is separated by sheets: tabular data on a "Report" sheet, charts on a "Chart" sheet, and logistic information on a "Report_Information" sheet. This is also a very nice layout.
CSV is obviously very bare bones, intended to be a raw source of data for any external apps that need to consume your intelligence data.
On a final note, for those who wish to access the PAS data using Excel natively, PAS actually publishes out an XMLA service that can be consumed within Excel. There is, however, no out-of-the-box connector to Excel that one could use. A software purveyor, Simba Technologies, has created a third party Excel connector (SimbaO2X) to XMLA sources that integrates right with Excel's PivotTable functionality. However, I did some tests with the latest version, and it does not play well with Excel 2010 -- I'm told a fix will be applied that will allow it to play well with Excel 2010. However, as of this writing, this connector is NOT usable with Excel 2010.
Consumption of Data Summary
Apart from the quirk we saw above with repeating dimensional attributes, I am a very big fan of the Pentaho Analyzer Report module on the Pentaho User Console. It's incredibly easy to navigate, functions are very intuitive, and the slice and dice capability is at the very least on-par with SSAS. The niceties, such as graphing, exporting, and saving off to the Pentaho repository for use in Dashboards is icing on the cake. This is a world-class data analytic tool.
Pentaho Analysis Services: The Good, The Bad, and The Weird
The Good
The real question we're trying to determine is if Pentaho Analysis Services is truly an enterprise-level analytic engine, especially from the eyes of someone who worked with SSAS for so long. While the engine does meet most all of the requirements set forth for the comparison (we're excluding the hierarchies issue and repeating dimensional attribute issue here, as I am new to Pentaho), the quality of documentation of the product is very uneven. While I understand that Pentaho does not have the backing of the billions that Microsoft possesses, at the very least, a proper starter's guide should have been written. As it stands, what you can find on the Knowledge Base, I feel, is very lacking, and I had to do a lot of trial and error and Googling examples from forums to get my schema "right enough".
Also, the development tools seem very lacking in comparison to Microsoft Business Intelligence Development Studio. As I mentioned in the start of the overview, whereas BIDS is a user-friendly, almost guided way to develop BI, Pentaho Schema Workbench is a rough, blank slate, leaving you to hang yourself in multiple, creative ways.
Finally, the big dealbreaker for me would be the security model. Simply put, Pentaho's solution for PAS security is unsatisfactory. It makes PAS seem like a completely separate module from the rest of the suite (not using the Pentaho user/role model in the User Console). While having a fast, efficient analytic engine is the primary objective, objective 1b should have been to properly integrate with the overall security model, as not EVERYONE should be able to see all analytic data. I don't know what Pentaho was thinking with this.
That being said, I would probably feel uncomfortable recommending PAS as an enterprise-level analytic engine for a large company. It is close to being very good, but I feel even in its current iteration (v4.1), it is still undercooked. This is a little frustrating, as I honestly want to like this platform. Analyzer is one of the best web-based analytic tools I've encountered, and the concept of the Pentaho User Console on top of it is very slick. However, the lack of a proper guided development process, quirks with creation of simple analytic artifacts such as hierarchies, the primitive security model, and the uneven documentation would be enough to scare most risk-averse enterprises away.
However, this does not mean I wouldn't recommend PAS outright. It still does many things very well, and as such, if a company already had a big investment in Java, Linux, and open source platforms or simply cannot afford the costs associated with running and maintaining SSAS, PAS would definitely deserve a fair shake, knowing that getting PAS up-to-par with industry standard analytic engines may require some custom development (specifically with the security).
Stay tuned for the next article -- SQL Server Analysis Services 2008 and a side-by-side comparison with Pentaho Analysis Services
Creating Hierarchies
When we get to the creation of the Sales Territory dimension, one will notice that it has a hierarchical structure. Specifically, our data is organized such that SalesTerritoryGroup is the parent of SalesTerritoryCountry. In turn, SalesTerritoryCountry is the parent of SalesTerritoryRegion. In this example, I've simplified the naming conventions to be Group, Region, and Country.
To define this hierarchical structure, assuming these fields are already created under the same default hierarchy as explained above, creating this tiered relationship is as follows in Schema Workbench:
- Click on the "Country" level under the DimSalesTerritory shared dimension.
- Click on the parentColumn attribute, then select SalesTerritoryGroup
- Click on the "Region" level
- Click on the parentColumn attribute, then select SalesTerritoryCountry
Unfortunately, defining the hierarchy in the Sales Territory dimension above gives us some drawbacks in the dimension. First, the way data will come up will only be if you first drop the Group attribute to an axis first, then the Country, then the Region. If you drop the Country attribute into an axis directly, your report will yield no data.
This is a little curious, as in the SSAS world, this does not happen. In fact, defining the hierachy in SSAS such as the above makes the parent-child relationships easier to read and has no effect on dropping any of the child attributes to an axis to slice and dice.
Again, my new-ness to Pentaho may have something to do with this, and I will explore a resolution of this hierarchy model as I understood it from SSAS. Until then, I will have to take points away from Pentaho for an unclear definition of how the hierarchies should be defined and consumed. For my model, I have just removed the hierarchy in the Sales Territory dimension altogether so that the slice and dice capability is at least usable for this dimension.
Applying Security
Security is also implemented with Pentaho Analysis Services. This obviously will be defined at the Schema level, as security spans across all cubes and dimensions. To setup our security such that only Resellers and Executives can actually see the ResellerSales cube, the following steps should be taken:
- Right click on the "Schema" node then click "Add Role"
- In the name of the new role, type in "Resellers"
- Right click on the Resellers role then click "Add Schema Grant"
- On the access attribute, select "none"
- Right click on the Schema Grant node, then click "Add Cube Grant"
- On the access attribute of the Cube Grant, select "all"
- On the cube attribute of the Cube Grant, select ResellerSales
One note about the security model -- it is not easy to implement out of the box. Per the Mondrian documentation, you can either embed the Role in the connection string or programmatically set it. All I could think of is how ugly this is. The security implementation of an analytic engine should be a basic implemented feature, but Mondrian appears to have a separate security model from the Pentaho User Console. This definitely may be a dealbreaker for many folks.
Publishing the PAS Schema
So, assuming you've completed the steps above for the rest of the dimensions within AdventureWorksDW2008 and linked it them up to the ResellerSales cube, we essentially have a ready to publish schema.
Publishing from Schema Workbench is relatively straightforward. Simply click File --> Publish. A popup window appears which asks you to specify the URL to your Pentaho User Console, the Publish Password, and a Username/Password combination with sufficient rights to publish.
 |
| Publishing options in Pentaho Schema Workbench |
Click OK, and Schema Workbench then makes a connection to your Pentaho repository. Finally, select a destination for this new schema, specify the named connection on your Pentaho server which the schema will use to aggregate its data, and optionally, publish this schema as part of PAS' XMLA service. Click on Publish, and then your schema will now be accessible as part of your Pentaho install.
 |
| The final step in publishing the Pentaho Schema |
Schema Creation/Publishing Summary
Admittedly, coming from the land of SQL Server 2008 BI, the development process feels incredibly cumbersome with Pentaho. The Schema Workbench should try to adopt something as smooth as an SSAS project on BIDS, whereby the developer simply adds all the dimension and fact tables visually on a view, drag and drop PK/FK relationships among the dimension and fact tables, then creates cubes based on this view, and then finally the tool should be smart enough to create the skeleton for all the dimensions with the fact measures linked up. The definition of the dimensional attributes, properties, and hierarchies should come after this quick vetting out process. It's a small thing, but the fact that Schema Workbench can't create a skeleton structure for me given a relational star schema is a bit annoying.
Anyway, creating your analytic schema will take a bit of time in Pentaho, even if it's a relatively simple star schema with nothing crazy related to hierarchies or calculated members. Calculated members are straightforward. However, the hierarchies, while straightforward to construct, don't seem to behave in the way that I would expect them to behave. Furthermore, the security model really is, for lack of a better term, primitive. I don't understand how PAS got through three version releases without implementing security integration with the rest of the Pentaho suite, it's just mind-boggling.
In terms of publishing the schema, the process is relatively straightforward from Schema Workbench. There doesn't appear to be an automated way of deploying cubes (as part of a Continuous Integration Server, for example), but the structure is relatively simple. The schema file itself is an XML file that will get dropped somewhere in the repository and making it available for consumption is a matter of updating the /pentaho-solutions/system/olap/datasources.xml file.
To sum up, the creation and publishing of the schemas in Pentaho, while functional, seems a bit rough around the edges. This might be slightly off-putting for anyone who came from the SQL Server BI platform first.
Consumption of Data
So, now we get to the fun part -- using the data schema we just published. We've got a nice Reseller Sales cube using a bunch of Shared Dimensions defined above and published to our Pentaho server. Let's do a little slicing and dicing!
The primary user interface for the Pentaho BI stack is the User Console. On a default install, it sits on port 8080 of your Apache Tomcat server. So, let's pop into the User Console and see where we can get at this data.

 |
| The Pentaho User Console looks very slick |
I must admit, this is one of the components of Pentaho that I've absolutely grown to love. In terms of user interface presentation and coherence, I believe Pentaho really has beaten Microsoft here. Whereas a SQL Server 2008 BI solution is disjointed from the start (until you develop some Sharepoint site to sit on top with a little PowerPivot and some SSRS reports), Pentaho feels...unified right out of the gate. Everything through the web-based User Console first.
We'll go into a deep dive of the Pentaho User Console in a later article which we review the overall "out of the box" user presentation of each platform, but from a preliminary perspective, I really prefer the Pentaho web-based UI.
The way to do some ad-hoc slice and dice analysis on a published cube on the User Console is simple. Click on New Analysis, select the cube, and you're off!

 |
| Voila! A blank analysis report |
The report obviously starts off blank, but if you're familiar with any analytic tool, the next part should be straightforward. Simply drop what measures you want to aggregate onto the report canvas. Afterwards, drop in whatever dimensional attribute you want along the row and column axes. For this example, let's measure Net Profit or Loss. Then, let's see the data by Department Name (off the Employee Dimension) across the rows and then by Fiscal Year across the columns.
 |
| Hmmm..repeating department names. |
Of course, this could be the way I designed the dimension, so I've floated up this question to the Pentaho Forums, hoping to gain insight, if it is indeed a system limitation or simply incorrect design on my part for the dimension. I will update this article as soon as I get a response back. If it is a system limitation, that would be a little disheartening, as this web-based analytic tool is otherwise brilliant.
To demonstrate its flexibility, let's slice out some data that won't produce repeat data. Let's measure Net Profit or Loss by Region (off of the Sales Territory dimension) on the column axis and then dragging the Fiscal Year dimensional attribute over to the row axis. Changing your sliced data is as simple as clicking and dragging the Department Name dimension from the row axis and into a garbage can that appears in the lower right hand corner. Then, drag the Fiscal Year dimensional attribute from the column axis to the row axis. Finally, drag over the Region dimensional attribute from the Sales Territory dimension and drop it on the column axis.
 |
| The ol' switcheroo |
Now, let's get a little fancy. Let's see this data plotted across a line graph. To do this, there is a Pie-Chart shaped icon on the upper right hand corner of the report (to the right of "View As"). To the right of this pie chart is a downward arrow. Click on the downward arrow then select "Line".

 |
| Very slick! |

Let's examine some export options. Web-based is nice and all, but at times, you will need to save off to a file format that can be read by stakeholders locally. The Analyzer Report offers the ability to export to PDF, Excel, or CSV. Simply click on the More option above the report, select Export Report, then select your desired format. See examples below of the export formats we can achieve.

Without going into too much detail, the PDF reports in particular look very slick, complete with a cover page, any graphs (like the one above) we create, and report parameters in the last page.
On Excel, the data is separated by sheets: tabular data on a "Report" sheet, charts on a "Chart" sheet, and logistic information on a "Report_Information" sheet. This is also a very nice layout.
CSV is obviously very bare bones, intended to be a raw source of data for any external apps that need to consume your intelligence data.
On a final note, for those who wish to access the PAS data using Excel natively, PAS actually publishes out an XMLA service that can be consumed within Excel. There is, however, no out-of-the-box connector to Excel that one could use. A software purveyor, Simba Technologies, has created a third party Excel connector (SimbaO2X) to XMLA sources that integrates right with Excel's PivotTable functionality. However, I did some tests with the latest version, and it does not play well with Excel 2010 -- I'm told a fix will be applied that will allow it to play well with Excel 2010. However, as of this writing, this connector is NOT usable with Excel 2010.
Consumption of Data Summary
Apart from the quirk we saw above with repeating dimensional attributes, I am a very big fan of the Pentaho Analyzer Report module on the Pentaho User Console. It's incredibly easy to navigate, functions are very intuitive, and the slice and dice capability is at the very least on-par with SSAS. The niceties, such as graphing, exporting, and saving off to the Pentaho repository for use in Dashboards is icing on the cake. This is a world-class data analytic tool.
Pentaho Analysis Services: The Good, The Bad, and The Weird
The Good
- Pentaho Analyzer is a killer application. Web-based (read: cross-platform), fast, responsive, and with a plethora of options, this module should be the envy of its competitors.
- The PAS engine seems to be very responsive, simple aggregations and calculations are on-par with leading BI tools
- XMLA service means that PAS is truly cross-platform out of the gate.
- A cumbersome development process, even with the Schema Workbench development environment. Pentaho should strive to create a development experience as smooth as BIDS.
- The operational options of a PAS cube seems limited. Whereas in SSAS, you can specify items like cube data partitioning, method of retrieving data (ROLAP, HOLAP, MOLAP), you're pretty much stuck with Pentaho's base functionality unless you muck up the source.
- Uneven documentation on the Pentaho website and Knowledge Base. Perhaps the formal courses offered by Pentaho are the way to go, but the literature available for Mondrian seems lacking, specifically for new users.
- No drillthrough capability in Pentaho Analyzer
- Almost laughably limited security model
- Repeating dimensional attributes?
- Issues displaying hierarchies on Analyzer?
The real question we're trying to determine is if Pentaho Analysis Services is truly an enterprise-level analytic engine, especially from the eyes of someone who worked with SSAS for so long. While the engine does meet most all of the requirements set forth for the comparison (we're excluding the hierarchies issue and repeating dimensional attribute issue here, as I am new to Pentaho), the quality of documentation of the product is very uneven. While I understand that Pentaho does not have the backing of the billions that Microsoft possesses, at the very least, a proper starter's guide should have been written. As it stands, what you can find on the Knowledge Base, I feel, is very lacking, and I had to do a lot of trial and error and Googling examples from forums to get my schema "right enough".
Also, the development tools seem very lacking in comparison to Microsoft Business Intelligence Development Studio. As I mentioned in the start of the overview, whereas BIDS is a user-friendly, almost guided way to develop BI, Pentaho Schema Workbench is a rough, blank slate, leaving you to hang yourself in multiple, creative ways.
Finally, the big dealbreaker for me would be the security model. Simply put, Pentaho's solution for PAS security is unsatisfactory. It makes PAS seem like a completely separate module from the rest of the suite (not using the Pentaho user/role model in the User Console). While having a fast, efficient analytic engine is the primary objective, objective 1b should have been to properly integrate with the overall security model, as not EVERYONE should be able to see all analytic data. I don't know what Pentaho was thinking with this.
That being said, I would probably feel uncomfortable recommending PAS as an enterprise-level analytic engine for a large company. It is close to being very good, but I feel even in its current iteration (v4.1), it is still undercooked. This is a little frustrating, as I honestly want to like this platform. Analyzer is one of the best web-based analytic tools I've encountered, and the concept of the Pentaho User Console on top of it is very slick. However, the lack of a proper guided development process, quirks with creation of simple analytic artifacts such as hierarchies, the primitive security model, and the uneven documentation would be enough to scare most risk-averse enterprises away.
However, this does not mean I wouldn't recommend PAS outright. It still does many things very well, and as such, if a company already had a big investment in Java, Linux, and open source platforms or simply cannot afford the costs associated with running and maintaining SSAS, PAS would definitely deserve a fair shake, knowing that getting PAS up-to-par with industry standard analytic engines may require some custom development (specifically with the security).
Stay tuned for the next article -- SQL Server Analysis Services 2008 and a side-by-side comparison with Pentaho Analysis Services
2 comments:
Check it once through MSBI Online Training Hyderabad for more info.
Thanks you for sharing the article. The data that you provided in the blog is infromative and effectve. Through you blog I gained so much knowledge. Also check my collection at MSBI online training Hyderabad Blog
Post a Comment